
Typically when comparing how engineering teams work from a deliverable perspective, there is not that much difference from team to team. Where there are differences these are usually just semantics. Essentially all engineering teams break large chunks of work into smaller chunks of work, assign these smaller chunks out to individuals or teams and then get on with delivering those chunks. These chunks of work are usually organised in a task tracking tool. Product design teams however, tend to work in a number of ways but generally the initial outputs they produce are not in the formats that the engineering team can use. This means a translation or conversion is required often involving the product team painstakingly converting their diagrams and models into epics and user stories or a similar format of chunks or tasks.
In order to avoid the translation perhaps we could design systems as we currently do and then develop these systems by directly assigning the designed components to developers / teams. There are, however, so many different great design approaches each with their own pros and cons depending on the context. This post does not aim to challenge or invalidate any of them but rather it aims to suggest a very specific and simple technique to use and then describes the scenarios in which this technique seems to work well.
So instead of asking engineering to adjust how they work in the aim of removing the translation, why not try and design the system in the format already being used by the engineering team which is typically epics and user stories or something similar?
As mentioned before, the Floodlight application requires the user to draw out a system process flow in the format of epics and user stories. This means the product team is encouraged to design the system in terms of a chronological data flow from a system user’s perspective. To do this the following steps are required:
- Identify the functional sections of the system that a user would move through chronologically when using the system. These will be the epics
- Then, identify the more detailed requirements of each of these functional sections which describe exactly what the user needs in order to move through the system, and why the user needs these requirements. These will be the user stories
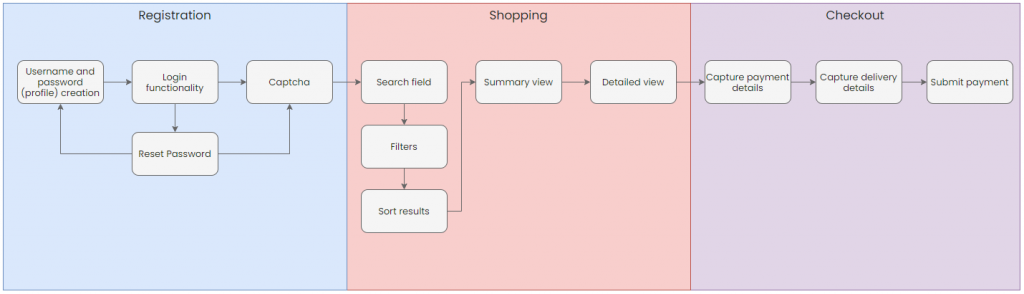
Below is a simple example using an online shopping system with the sections being epics and the line items being user stories:
- Registration
- Username and password (profile) creation
- Login functionality
- Reset password
- Captcha
- Shopping
- Search field
- Filters
- Sorting
- Summary view
- Detailed views
- Checkout
- Payment details capture
- Delivery details capture
- Returns FAQs
Each of these inner blocks or stories could and probably should be broken down further into more granular detail. If that is the case then this should be done first in a visual way and then in the user stories. This is a very helpful technique in establishing how-low-should-you-go? You don’t want to have a user story that is so granular that it actually doesn’t achieve anything on its own. A general rule of thumb when discussing how low you should go (detail-wise), is as low as possible while retaining the ability to deploy and test the story on its own. This is something we call “functional independence”, i.e. can function on its own.
An example to illustrate this could be an input field for a credit card number with validation.
As a shopper I want the ability to enter my credit card number into a field and have it recognised as a credit card to avoid typos so that I can complete my purchase
Now, this can clearly be broken into 2 separate user stories, one for the input field itself, and another for the validation:
As a shopper I want the ability to capture my credit card number so that I can complete my purchase
AND
As a shopper I want my credit card to be validated as a credit card when I type it in so that I avoid making typos and so that the type of credit card is auto populated.
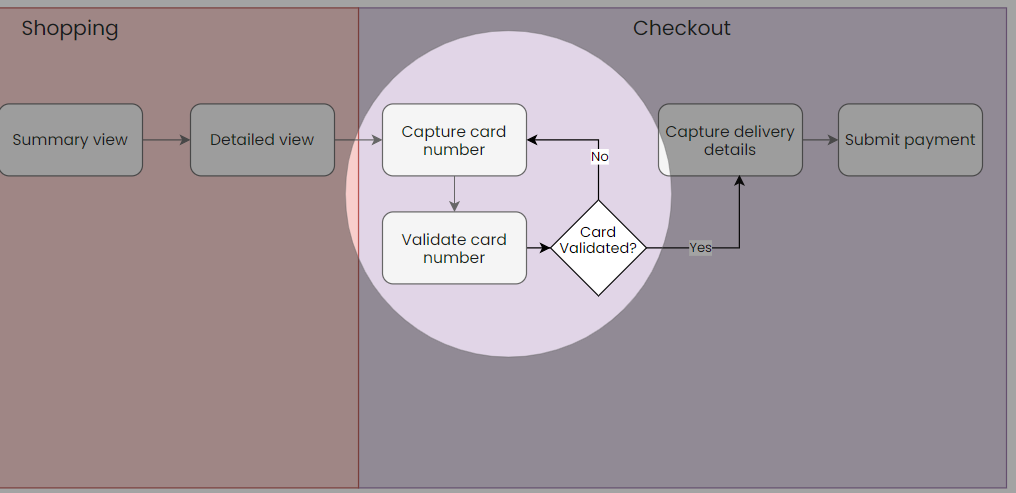
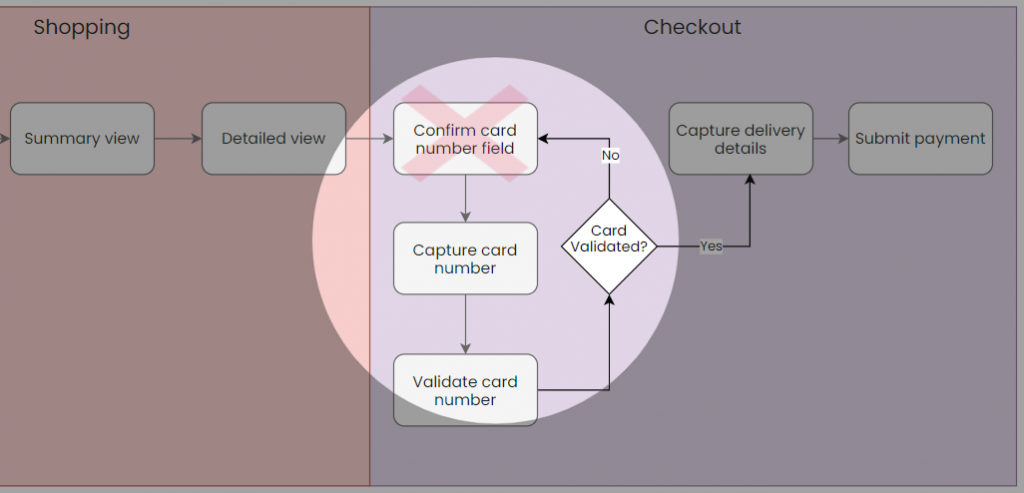
Can the first story be broken down further while retaining its functional independence? Well not really if it needs to work on its own. We could perhaps say:
As a shopper I want a field to capture my credit card number so that I can complete my purchase
AND
As a shopper I want the ability to enter my credit card number into a field so that I can complete my purchase
The first story focuses on the fact that there needs to be a field there while the second focuses on the ability to enter the number. It would be quite confusing for a team to try and separate these two, but imagine trying to test these two things independently of each other.
Test 1: Is there an input field on the page? Yes, can I enter a number into it? No. Regardless the test has passed
Test 2: Can I enter my number into the field? Well only if test 1 above has passed (and fulfilled this very test).
This may seem a bit convoluted but it’s a common challenge for product teams and this test of functional independence is useful.
Back to the drawing board (literally). Try to draw the first two stories which we have established do have functional independence. It’s quite easy. Now try draw the latter two. It’s not really possible to do it in a way that makes sense is it?
So, again, while there are many powerful system design tools and techniques, most of the time, system requirements end up in the form of epics and user stories so why not just start out with this format and avoid a translation effort. We’ve engineered Floodlight – Live diagrams for Jira with this in mind.
Try Floodlight here
Comments are closed.